【新智元导读】越来越多研究发现,后训练对模型性能同样重要。Allen AI的机器学习研究员Nathan Lambert最近发表了一篇技术博文,总结了科技巨头们所使用的模型后训练配方。
随着LLM学界和工业界日新月异的发展,不仅预训练所用的算力和数据正在疯狂内卷,后训练(post-training)的对齐和微调方法也在不断更新。
InstructGPT、WebGPT等较早发布的模型使用标准RLHF方法,其中的数据管理风格和规模似乎已经过时。
最近几个月来,Meta、谷歌和英伟达等AI巨头纷纷发布开源模型,附带发布详尽的论文或报告,包括、、,以及Apple Intellegence的基础模型报告。
从这些披露的信息中,我们可以看到后训练方法的一些前沿变化趋势。Allen AI研究科学家Nathan Lambert最近就这个话题发布了一篇文章。

原文地址:https://www.interconnects.ai/p/frontier-model-post-training

Nathan Lambert博士毕业于UC伯克利,曾在HuggingFace领导RLHF团队,目前是Allen AI的机器学习研究员。
他在文章中指出,合成数据、迭代训练、人类偏好标签和大量过滤,是这些模型所用后训练方法的共同特点。具体来说,新的后训练配方建立在以下预设的基础上:
- 合成数据的质量可能高于人类数据,特别是对于具有挑战性的任务
- RLHF可以比指令微调扩展到更大规模
- 需要多轮训练和生成才能得到最佳模型
- 数据过滤是训练中最重要的部分
这些假设在很大程度上相互交织,构成了可以扩展到大型团队的训练方案,非常适用于科技巨头。文章的具体内容对以上四点分别做出了详细阐释。
新的标准Pipeline
如果我们认为ChatBot Arena分数衡量了模型的后训练表现,这就很大程度上与风格和鲁棒性相关,几乎所有的主要实验室都通过迭代训练获得了显著收益。
我们还没有看到Gemini 2或GPT-5发布,它们也许会重置目前的后训练范式,并有可能解锁我们对模型更深层次的控制能力。
但从目前来看,各个顶级实验室所用的方法明显趋同,这种趋势比预期中要清晰得多。
人类偏好数据
最初的RLHF管道的重点是人类数据,主要有两种形式:1)用于对专门任务进行指令微调的人类数据;2)有关任务完成度的人类偏好数据。
这类微调数据集成本高昂且被严格保护,据我所知,唯一的公开的应该只有Lambert在HuggingFace团队时发布的No Robots。
仓库地址:https://huggingface.co/datasets/HuggingFaceH4/no_robots
人类偏好数据很大程度上与特定模型的改进有关。但即使在数据可以开放的情况下,也不能确定可以将一个模型的偏好迁移至另一个模型。
Lambert在HuggingFace时曾和团队做过类似的尝试,但在小型付费数据合同上失败了。
现在,唯一用到人类数据的方面就是偏好数据。从Llama 2披露的数据和其他传闻来看,Meta可能在偏好数据上花费了10M-20M美元,甚至更多。这还仅限于最终发布的模型,不包括更广泛的实验和评估。
Nemotron则使用大量合成数据来替代人类数据,但相对而言,这个模型的微调并不那么出色。
对开放社区而言,有一个迫在眉睫的挑战,但同时也是机遇:弄清这类数据中的人为干预的程度,能否用LLM-as-a-Judge或奖励模型等方法代替。
扩展RLHF
Llama 3的对齐负责人Thomas Scialom在播客节目Latent Space上曾说道:
RLHF的可扩展性要高得多。它成本更低、更容易操作,并且通常会带来更好的性能。

他还表示,自己会将「100%的对齐数据预算用于RL阶段所需的对齐数据,而不是在指令上花费更多时间。」
开源的对齐工作中大多专注于扩展指令微调(IFT,或称为 SFT)。IFT容易操作、适用于多种任务,而且方便与合成数据共同使用。
但很明显,产业界仅将IFT作为扩展RLHF的起点。SFT数据主要关注以前模型未能覆盖的特定领域,然后在此基础上扩展RLHF。
RLHF是一个迭代过程,模型的生成过程可以让它继续改进。Llama 2和 Nemotron论文中详细介绍了5轮训练,但我们不知道这个数字是否有上限。
Llama 3.1进行了6轮偏好数据的训练,Llama 2是5轮,Nemotron是4轮,之前还有多轮指令微调。
对于人类偏好数据而言,进行多轮迭代可能主要出于可行性方面的考量:
1. 数据从注释公司分批传送到实验室
2. 进行多轮小规模的训练可以降低最终产品交付的风险。与其等待所有数据到位后才开始训练,不如让模型逐渐步入正轨
这类现实因素看起来无关紧要,但往往会触发某种行业规范。
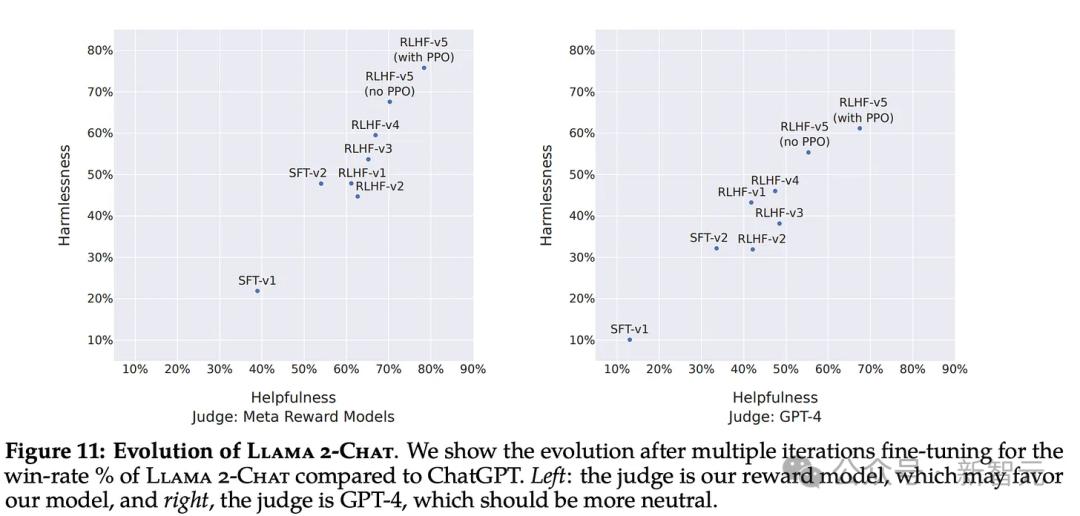
下面这张图片来自Llama 2论文,记录了5轮拒绝采样和PPO相关的数据。
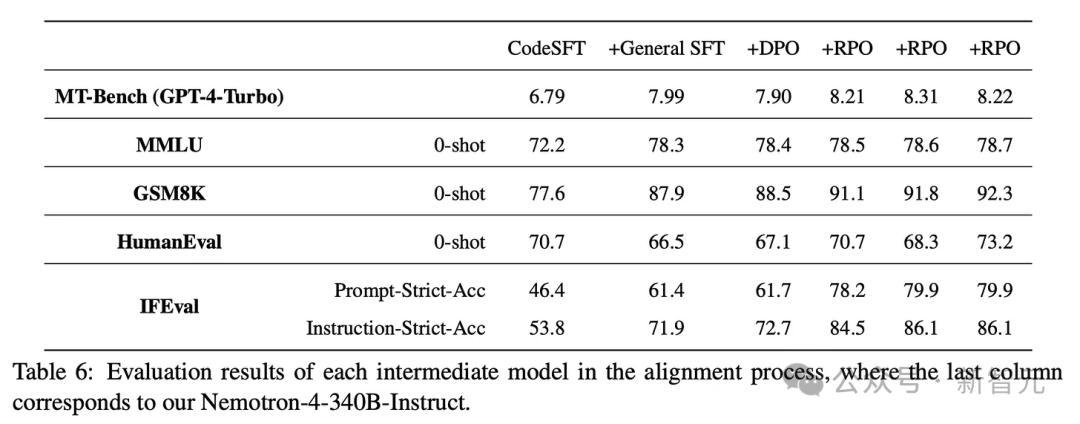
Nemotron还进行了2轮SFT微调和4轮对齐。其中,RPO是用DPO优化器加权的奖励模型。
类似的迭代RLHF方法可以追溯到Anthropic提出的「宪法人工智能」,但开源社区似乎没有大规模复现这个结果。

目前,学术界正在关注「在线DPO训练」,这在方向上是相似的,但对各轮之间数据没有那么关注。这种方法目前仍需要大量手动操作,但一旦实现流程自动化,在线DPO将成为未来。
事实上,各个团队对后训练阶段的算法选择不应该如此一成不变。DPO和PPO各有优劣,前者更容易扩展,但PPO启发的方法(如在线RL)具有更高的性能上限。
目前这些方案主要出于简洁性考量,因为这些团队仍然相对较新并且正在构建模块化系统,Llama 3后训练团队中一名成员的说法也证实了这种具备工程简洁性的方法。

Llama 3有一个简单的后训练循环:拒绝采样、SFT 和 DPO。这不仅在经验层面有最佳性能,还实现了可复现性。而且,团队可以异步探索许多不同的工作流(例如编码、数学),将数据汇集到同一个简单的循环中。
合成数据
这种新的RLHF循环中,很重要的一环是在大多数任务上超越人类能力的合成指令数据。
如果可以让模型有一点点提升、生成更好的指令,那就「重新开始」,更新检查点。
Meta在论文中明确表示,他们「使用405B模型来提高我们较小模型的后训练质量」;谷歌通过蒸馏出Gemini Flash来做到这一点,但实际上大多数前沿模型可能都包含一些类似步骤。
我听说OpenAI正在使用50万亿token的数据训练下一代模型,其中大部分为合成数据。去年有一个传言,Anthropic拥有「预训练规模的宪法AI语料库」,现在看来这也很合理。
这些AI公司意识到合成数据的重要性应该是在12~18个月之前,当他们不再使用模型输出进行自我迭代训练的时候。但Meta不一样,因为受益于其他更好的开放模型。
看看当今的后训练就可以清楚知道,合成数据造成模型崩溃的问题被过分夸大了。只有在人为设置的环境中,丢弃原始数据、只留下生成的新数据时,才会发生模型崩溃。
数据质量是王道
Llama 3.1报告的大部分内容都是关于数据管理的细节,其中每个相关的子领域都需要广泛而具体的管理说明。
这与我所知的OpenAI John Schulman领导的后训练团队以及其他类似团队的工作情况相符——指定一个特定领域,获得相关数据,然后模型就会变得更好。
但如果没有大量的数据过滤和管理,上述的RLHF方法都不起作用。
在Allen AI,我们在后训练流程中开始更加优先考虑数据,可以立即感受到模型提升速度的变化。
案例分析——Nemotron和Llama
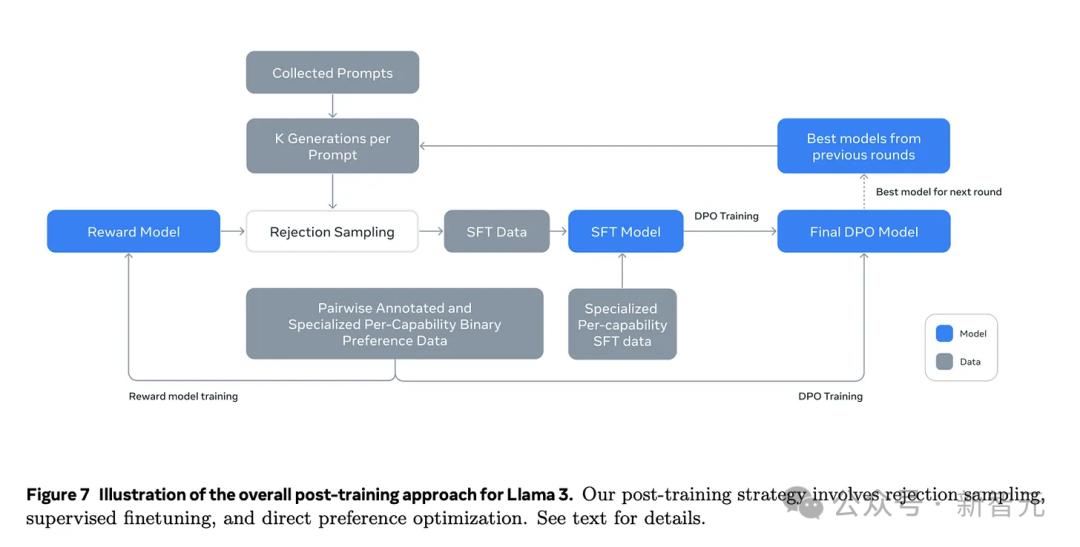
Llama的后训练流程如下:
Nemotron的这张图比较简略:
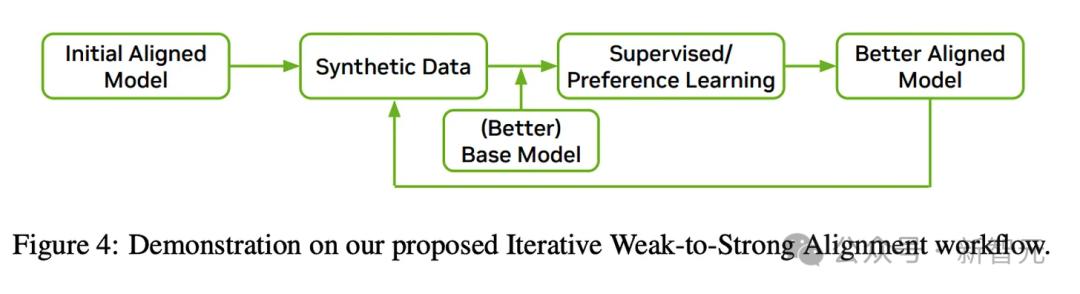
综合起来可以看到大多数方法的共同点。
但下面这张图表,以及大多数行业研究论文都忽视了数据。
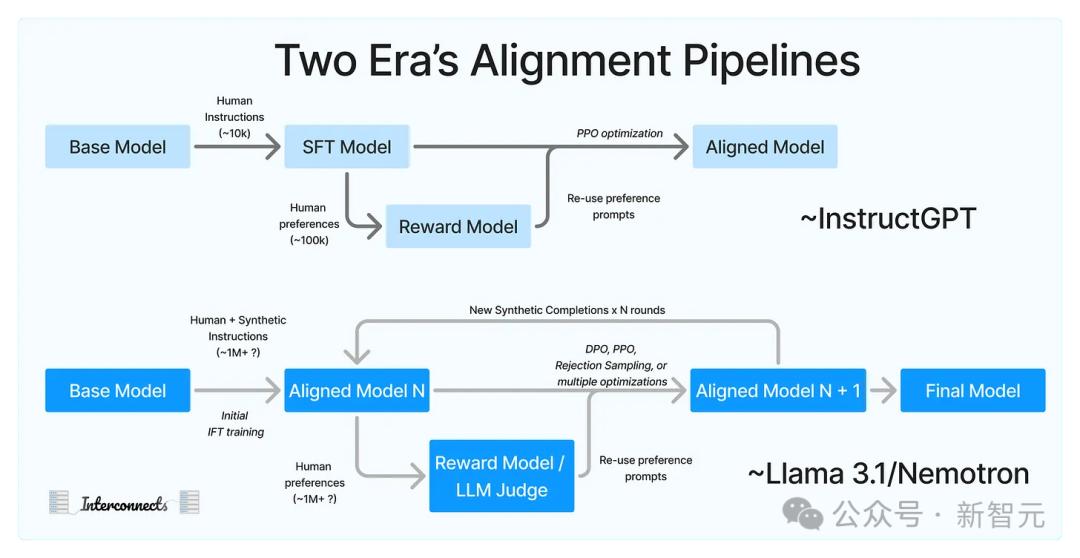
Llama 3.1等模型到报告中有提及了很多细节,比如正则化、对损失函数的调整、模型平均等等,但这些都是模型性能的边际收益,很大程度上超出了核心微调循环的范围。
